
布隆过滤器误判解决方案,布隆过滤器误判率分析与优化策略
在数字信息的海洋中,你是否曾想过如何高效地判断一个元素是否存在于庞大的集合中,而又不希望被大量的数据淹没?布隆过滤器,这个看似神秘的数据结构,正是为此而生。它以其独特的空间效率和查询速度,成为了大数据时代不可或缺的工具。但正如任何强大的工具一样,布隆过滤器也有其弱点——误判。今天,就让我们一起深入探索布隆过滤器误判的解决方案,揭开其背后的奥秘。
布隆过滤器的世界

想象你正在经营一家大型电商平台,每天有数以百万计的商品被浏览和搜索。为了提升用户体验,你希望避免用户重复浏览已经看过的商品。这时,布隆过滤器就派上了用场。它通过一个位数组和一系列哈希函数,快速判断一个商品是否已经被浏览过,而无需存储所有商品的信息。这种高效性使得布隆过滤器在缓存穿透、爬虫去重等场景中得到了广泛应用。
布隆过滤器并非完美无缺。它的误判特性,虽然在一定程度上可以接受,但仍然需要我们认真对待。误判,意味着一个本不存在的元素被错误地判断为存在,这可能导致不必要的数据库查询或重复工作,影响系统的性能和用户体验。
误判的根源
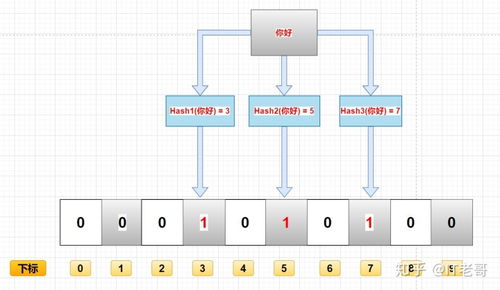
要理解布隆过滤器的误判,首先需要了解其工作原理。布隆过滤器使用多个哈希函数将一个元素映射到位数组的不同位置。如果多个元素通过不同的哈希函数映射到同一个位置,位数组在该位置就会被置为1。查询时,如果所有哈希函数都映射到位数组为1的位置,布隆过滤器就会认为该元素存在。反之,如果任何一个哈希函数映射到位数组为0的位置,就可以确定该元素不存在。
误判的产生,源于哈希函数的碰撞。当多个不同的元素通过不同的哈希函数映射到同一个位置时,位数组在该位置就会被置为1。查询时,如果另一个本不存在的元素通过相同的哈希函数映射到该位置,布隆过滤器就会误判它为存在。
降低误判率的策略
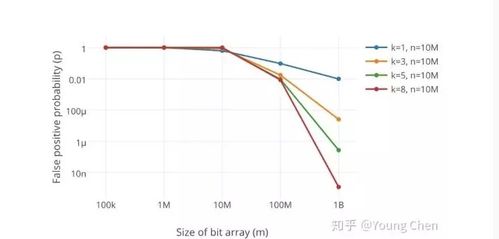
降低布隆过滤器的误判率,需要从多个角度入手。首先,增加哈希函数的数量是一个有效的方法。更多的哈希函数可以减少哈希碰撞的概率,从而降低误判率。但需要注意的是,哈希函数的数量并非越多越好。过多的哈希函数会增加计算开销,反而影响性能。因此,需要在误判率和性能之间找到平衡点。
其次,增大位数组的长度也是一个可行的策略。位数组越长,哈希碰撞的概率就越低。但位数组长度的增加也会占用更多的内存空间,因此需要根据实际可用的内存资源进行合理选择。
此外,合理设计哈希函数也是降低误判率的关键。选择具有良好分布特性的哈希函数可以减少碰撞的发生。例如,MD5、SHA-1等哈希函数都具有较好的分布特性,可以用于布隆过滤器。
实际应用中的解决方案
在实际应用中,降低布隆过滤器的误判率需要结合具体场景和数据特性进行综合考虑。例如,在网络爬虫场景中,为了避免重复爬取已经访问过的URL,可以使用布隆过滤器进行快速判断。但为了降低误判率,可能需要增加哈希函数的数量或增大位数组的长度。
在缓存穿透场景中,布隆过滤器可以用来避免对不存在的数据进行数据库查询。为了降低误判率,可以采用上述策略,并根据实际需求进行调整。
布隆过滤器的未来
随着大数据时代的到来,布隆过滤器的重要性日益凸显。虽然它存在误判的弱点,但通过合理的优化和设计,可以有效地降低误判率,使其在更多场景中发挥重要作用。未来,随着技术的不断发展,布隆过滤器可能会得到更多的改进和应用,为我们的生活带来更多便利。
在探索布隆过滤器的过程中,我们不仅了解了其工作原理和误判的根源,还掌握了降低误判率的策略。通过这些知识,我们可以在实际应用中更好地利用布隆过滤器,提升系统的性能和用户体验。让我们一起期待布隆过滤器在未来的更多创新和应用吧!