
布隆过滤器应用场景,高效数据存在性检测与多种应用场景解析
想象你正在浏览一个庞大的网站,每一次点击都可能导致数据库被大量查询,这会消耗多少资源啊!这时候,布隆过滤器就像一位聪明的守门员,帮你快速判断数据是否存在,避免不必要的麻烦。布隆过滤器是一种空间效率极高的概率型数据结构,它通过位数组和哈希函数来判断一个元素是否存在于集合中。今天,就让我们一起探索布隆过滤器的应用场景,看看它是如何在各种场景中发挥作用的。
布隆过滤器在缓存系统中的应用

在互联网时代,缓存系统扮演着至关重要的角色。你有没有想过,每次访问一个网站时,为什么页面能那么快地加载出来?这得益于缓存系统。但是,如果缓存中没有你想要的数据,系统就会去数据库中查询,这会消耗大量的资源。这时候,布隆过滤器就能派上用场了。
布隆过滤器可以预先判断某个数据是否存在于缓存中。如果布隆过滤器表示数据可能存在,那么系统再去查询缓存;如果布隆过滤器表示数据一定不存在,那么系统就直接返回,避免了不必要的查询操作。这样一来,不仅提高了系统的效率,还减轻了数据库的负担。
布隆过滤器在垃圾邮件过滤中的应用
垃圾邮件过滤是另一个布隆过滤器的应用场景。你每天收到的邮件中,肯定有不少是垃圾邮件。这些垃圾邮件不仅浪费你的时间,还可能带来安全风险。布隆过滤器可以帮助你快速识别垃圾邮件。
具体来说,你可以将已知的垃圾邮件地址存入布隆过滤器中。当收到一封新邮件时,你可以通过布隆过滤器快速判断这封邮件的地址是否在垃圾邮件列表中。如果布隆过滤器表示地址可能存在,那么你可以进一步检查邮件内容;如果布隆过滤器表示地址一定不存在,那么你可以直接将其标记为垃圾邮件,从而提高过滤效率。
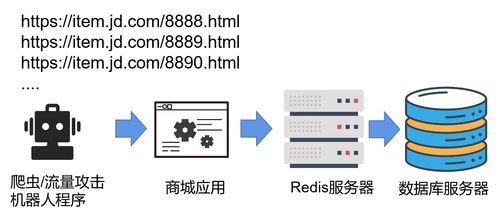
布隆过滤器在网页爬虫中的应用

网页爬虫是互联网数据采集的重要工具。你有没有想过,为什么爬虫能那么高效地采集数据?这得益于布隆过滤器。布隆过滤器可以帮助爬虫快速判断一个URL是否已经被爬取过,避免重复爬取。
具体来说,你可以将已经爬取过的URL存入布隆过滤器中。当爬虫发现一个新的URL时,你可以通过布隆过滤器快速判断这个URL是否已经被爬取过。如果布隆过滤器表示URL可能存在,那么你可以进一步检查这个URL;如果布隆过滤器表示URL一定不存在,那么你可以直接将其加入爬取队列,从而提高爬取效率。
布隆过滤器在分布式系统中的应用
在分布式系统中,布隆过滤器也发挥着重要作用。分布式系统通常由多个节点组成,每个节点都需要存储和处理数据。这时候,布隆过滤器可以帮助你快速判断一个数据是否存在于某个节点中,从而减少网络传输开销。
具体来说,你可以将每个节点的数据存入布隆过滤器中。当需要查询一个数据时,你可以通过布隆过滤器快速判断这个数据是否存在于某个节点中。如果布隆过滤器表示数据可能存在,那么你可以直接查询该节点;如果布隆过滤器表示数据一定不存在,那么你可以直接放弃查询,从而提高查询效率。
布隆过滤器在数据库查询优化中的应用
数据库查询优化是另一个布隆过滤器的应用场景。在数据库中,查询操作是非常常见的。但是,如果查询操作过多,就会消耗大量的资源。这时候,布隆过滤器就能派上用场了。
布隆过滤器可以作为辅助索引,预判查询的必要性。具体来说,你可以将数据库中的数据存入布隆过滤器中。当需要查询一个数据时,你可以通过布隆过滤器快速判断这个数据是否存在于数据库中。如果布隆过滤器表示数据可能存在,那么你可以进一步查询数据库;如果布隆过滤器表示数据一定不存在,那么你可以直接放弃查询,从而提高查询效率。
布隆过滤器是一种非常实用的数据结构,它在各种场景中都能发挥重要作用。无论是缓存系统、垃圾邮件过滤、网页爬虫、分布式系统还是数据库查询优化,布隆过滤器都能帮助你快速判断数据是否存在,提高系统的效率。当然,布隆过滤器也有一定的误判率,但只要合理配置参数,就能将其降到最低。让我们一起用好布隆过滤器,让数据管理变得更加高效!